

Concept Refactoring

If you've ever maintained a Wiki, you've probably noticed that there is a lot of refactoring involved. Ideas are written down in one place, then rewritten, moved, titles changed, links redirected, pages split and merged.
Hypertext wants to be refactored. This is a feature of hypertext, not a bug. Through constant refactoring, knowledge in a hypertext network evolves to find the right packets for a given domain, where one packet = one idea.
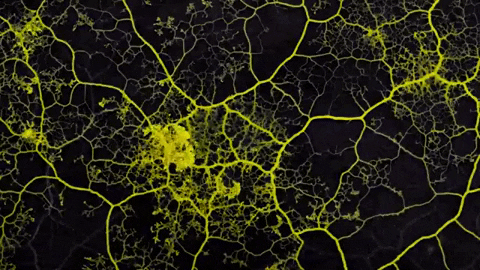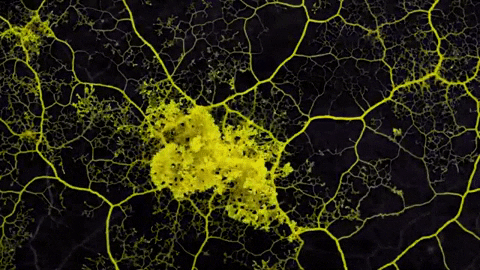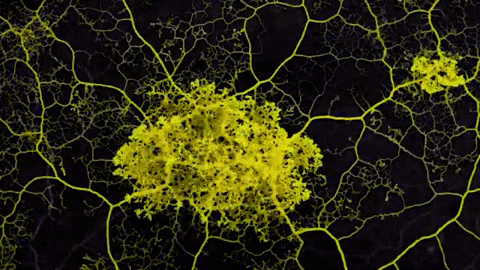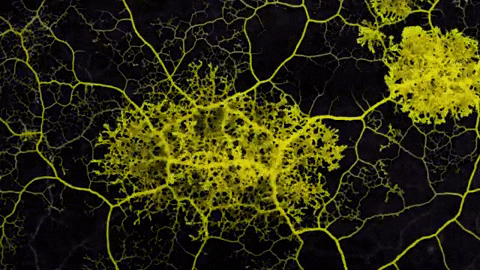
Where does one idea begin and the other end? It depends upon your point of view.
In an important sense there are no "subjects" at all; there is only all knowledge, since the cross-connections among the myriad topics of this world simply cannot be divided up neatly. Hypertext at last offers the possibility of representing and exploring it all without carving it up destructively.
Ted Nelson, 1974, “Computer Lib/Dream Machines”
Reality is too squishy and hyperdimensional to carve up into neat Platonic forms. Still, we end up building maps in an effort to make sense of things. The kind of map you construct depends upon what you’re trying to see.
We must not use the word system, then, to refer to an object… It is not a special kind of thing, but a special way of looking at a thing. It is a way of focusing attention on some particular holistic behavior in a thing, which can only be understood as a product of interaction among the parts.
Christopher Alexander, 1968, Systems Generating Systems
So a hypertext network might be seen as a map constructed to describe more numinous territory… the indivisible, interdependent, mutually arising phenomena of ideas and experience. The map answers an implicit question. Refactoring lets us construct both our question and our answer through organic exploration.
Prose is a kind of map too. It flattens N-dimensional thoughts into a 1D sequence of words. But unlike prose, which is mostly static, hypertext is evolvable. The map evolves to fit changing goals and changing territory.
What does hypertext refactoring look like? At the document level:
Factoring out documents. Notes often start out as a jumble of ideas. As a note evolves, separate ideas are factored out into their own notes.
Merging documents: notes taken during different times can often end up capturing similar ideas, or elaborating on the same idea. We want to merge these.
At the content level:
Adding links to related pages (links can be suggested)
Changing links to pages that have moved (often automated)
Rearranging content, typically paragraph-scale blocks, or items in a list.
Adding content, typically a bit of information to the end of a document, or at the end of a list.
Removing content
Rewriting content
Note that if we look at this in terms of Capture, Organize, Synthesize, many of these actions are capture and organize. Capture and organize are both modular, rather than holistic actions. They don’t require too much context to get right — a perfect opportunity for software to assist creativity. Imagine if your tool for thought could:
Add or suggest related links
Fix broken links
Suggest when an idea could be factored out into a document
Suggest when related documents could be merged
It’s easy to imagine half a dozen other opportunities for software to augment or even automate hypertext refactoring.
Rewriting may be trickier, because it requires holistic synthesis that spans the boundaries of any single idea, paragraph, or page. This requires careful creative judgement. But even here we can imagine surfacing creative suggestions as you type.
If we want to augment or automate refactoring, we need a way to structure text into logical blocks that can be factored out, merged, added, rearranged, removed. And so… Subtext.
A plain text file is more or less a single blob. Without any formal structure, it is difficult for a computer to understand what can be re-arranged, what can be factored out.
HTML is on the other end of the spectrum. It has structure—a tree of nodes. In theory, this should make it meaningful to a computer. In practice, since the structure is arbitrarily complex, it is difficult to make sense of the content without a lot of context. Try merging two HTML pages. Tag soup!

So, more structural variation means more context is required to determine the meaning of the structure. Infinite structural variation requires a nearly human-complete level of context to understand meaning.
What if we introduced the minimum amount of structure for working with text? Something simple for people, simple for computers, and meaningful for both?

That is my goal in experimenting with this new markup language, Subtext. Not formatting, but a kind of minimal markup for making notes legible so software can help you refactor them. “CSV for thought”.